

Die Erforschung und Anwendung von Künstlicher Intelligenz im Kontext von Visual Computing und Datenanalyse ist ein zentrales Thema des VRVis. Wir verfügen durch unsere hauseigene Grundlagenforschung sowie die Entwicklung und Implementierung etlicher KI-basierter Lösungen für reale Herausforderungen unserer Unternehmenspartner im In- und Ausland über umfangreiches Know-how und können bereits auf mehrere Patente und eine große Anzahl an Publikationen in hochkarätigen Wissenschaftsmedien zurückblicken. Unsere Stärken sind dabei unsere Vielseitigkeit und unsere Erfahrung in verschiedenen Branchen und mit unterschiedlichsten Anwendungsfällen: von Medizin und Life Sciences über den Einsatz im Business-Bereich bis hin zur industriellen Fertigung, der digitalen Agrarwissenschaft oder in der Weltraumforschung.
Neben generellen neuen Ansätzen für Machine Learning und Deep Learning zur Datenanalyse, forschen wir auch an KI-gestützter 3D-Rekonstruktion und bildbasierter Entscheidungsfindung sowie Methoden für interpretierbare AI (z.B. für KI-gestützte Assistenzsysteme). Die Verbindung von Künstlicher Intelligenz und Visual Computing schlägt eine Brücke zwischen Computergrafik, visueller Datenanalyse und KI. Im Mittelpunkt aller unserer KI-Anwendungen steht der Mensch, dem die Maschine zuarbeitet (Human Centered-AI). Künstliche Intelligenz bringt neue technologische Dynamik in viele Branchen – ganze Märkte werden derzeit von KI-basierten Anwendungen transformiert. Als AI-Hub deckt das VRVis Portfolio die gesamte Pipeline für KI-gestützte Datenanalyse ab.
Unser Portfolio für die komplette Pipeline KI-gestützter Datenanalyse

Datenvorbereitung
Die Qualität der Trainingsdaten im Kontext der jeweiligen Anwendung ist entscheidend für die Qualität des Ergebnisses. Unsere Erfahrung und die Anwendung elementarer Data Science-Techniken sowie Tools, die die Daten-Annotierung durch Expertinnen und Experten erleichtern, sind die Basis für die Aufbereitung von ausreichend viel "Big Data" und die Zusammenstellung adäquater Trainingssets.

Erzeugung von Trainingsdaten für KI-Systeme
KI-Lösungen sind nur so gut, wie die Daten, mit denen sie trainiert werden. Doch gute Trainingsdaten sind oft Mangelware, teilweise gar nicht verfügbar oder nur schwer/teuer zu beschaffen. Wir unterstützen unsere Unternehmenspartner, indem wir die notwendigen Daten künstlich simulieren, um neuronale Netze zu trainieren. Synthetische Daten sind sicher, anonymisiert und unbürokratisch. Die künstlich erzeugten Trainingsdatensets zeichnen sich durch eine sehr gute Datenqualität aus und helfen so, Innovationsprozesse zu beschleunigen, indem sie durch ihre schnelle Verfügbarkeit beispielsweise den time-to-market stark verringern.

Entwicklung maßgeschneiderter KI-Lösungen
Wir entwickeln Deep Learning- und Machine Learning-Technologien in enger Kooperation mit unseren Partnern sowie Kundinnen und Kunden, um gezielte Lösungen zum Verarbeiten, Analysieren und Visualisieren von großen Datenmengen und mehrere Terabyte umfassende Laserscandaten als auch für die Bildanalyse zu entwickeln.
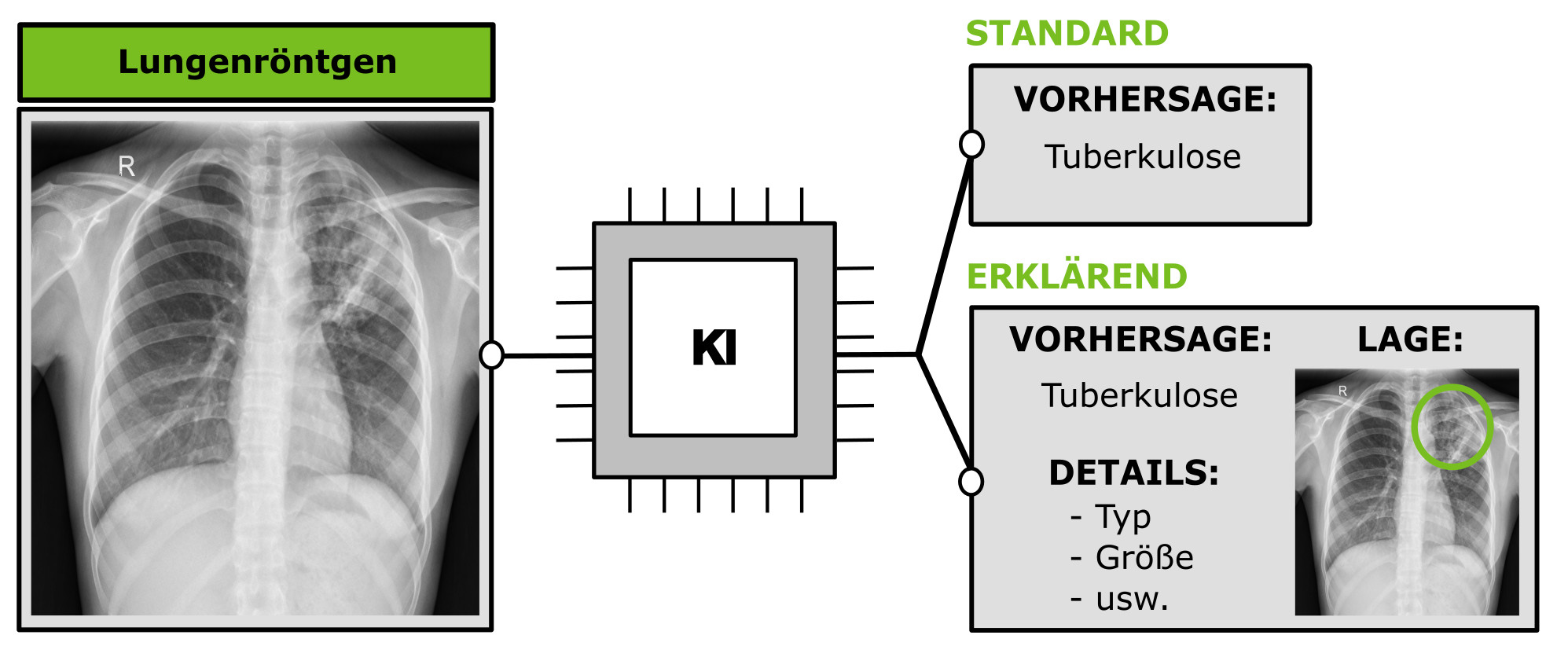
Explainable Artificial Intelligence (XAI)
Entscheidungen, die von Maschinen getroffen werden, sollen vor allem in sensiblen Bereichen, wie der Medizin oder bei selbstfahrenden Fahrzeugen, für den Menschen verständlich, zuverlässig und transparent bleiben ("Ethische KI"). Wir entwickeln Methoden, die maschinelles Verhalten erklärbar und so komplexe Entscheidungen, die mit Hilfe künstlicher Intelligenz getroffen werden, nachvollziehbar machen. Unsere Methoden unterstützen die Beurteilung von Sicherheit und Stabilität trainierter Netzwerke.
An unserem Forschungszentrum sind bereits mehrere KI-basierte Anwendungen, Patente sowie High-Impact-Publikationen in den Bereichen Bildverarbeitung, Data Science, und Punktwolkensegmentierung ebenso wie den Anwendungsgebieten Digital Radiologie, Neuroscience, Life Sciene, Materialwissenschaft und Industrie, Trainingsdatenerzeugung und digitale Landwirtschaft entstanden.

Schädlinge oder Extremwetter beeinflussen das Getreidewachstum und die Erträge. Die Pflanzenentwicklung zu erfassen und auszuwerten liefert die Basis, um Ernteeinbußen zu verhindern. VRVis ist Teil eines Projektkonsortiums, das eine Plattform für die Landwirtschaft entwickelt, mit dem Ziel, funktionelle Bildgebungsdaten zur Analyse zu nutzen und Kompetenzen dazu in Trainings zu vermitteln.
Klimawandelbedingt werden Extremwetterereignisse häufiger und neue Schädlinge setzen sich in der Landwirtschaft durch. Zusammen mit drei Projektpartnern entwickelt das VRVis ein digitales Bildgebungssystem für Pflanzen, das Informationen aus Magnetresonanztomographie und Positronen-Emissions-Tomographie kombiniert und Stresssymptome bei Pflanzen früh erkennt.
Im European Digital Innovation Hub "AI5production" haben sich 17 renommierte Wissenschaftsinstitutionen zusammengeschlossen, um produzierende Unternehmen durch KI-Technologie auf ihrem Digitalisierungsweg zu unterstützen.
Das im Rahmen von „AI for Green“-geförderte Forschungsprojekt entwickelt KI-basierte Lösungen für die Optimierung von freien Satellitendaten für das Monitoring von Agrarflächen aller Größen.
Das Projekt REINFORCE erforscht, wie mithilfe von Reinforcement Learning und menschzentrierte Visualisierungsmethoden komplexe Steuerungsprobleme effizient, schnell und flexibel gelöst werden können.
Im Zentrum des Forschungsprojekts CognitiveXR steht die Entwicklung einer Plattform, die kognitive Augmentation im Smart-City-Bereich durch nahtlose Integration von Augmented Reality, Edge Computing und Künstlicher Intelligenz ermöglicht.
Das Ziel des Anwendungsprojekts IVC Multi ist die Erforschung neuartiger intelligenter Visual Computing-Methoden zur Unterstützung der Entscheidungsfindung in der Automobilindustrie, der Medizin und den Biowissenschaften auf Basis von Ensembles heterogener, multiskaliger und/oder multitemporaler Daten.
Das Ziel des Projekts IVC Stream ist die Erforschung neuartiger Visual Computing-Lösungen für Simulations- und Messdaten.
Dieses Projekt IVC Image zielt auf die Beschleunigung und Automatisierung bildbasierter Entscheidungsfindung mit einem Anwendungsschwerpunkt in der Medizin sowie Recycling- und Qualitätssicherungsprozesse in der Fertigung.
Das strategische Projekt IVC Complex ist der Dreh- und Angelpunkt für die Realisierung des flächendeckenden intelligenten Visual Computing-Ansatzes für Analytik und Modellierung auf der Basis von Ensembles aus dichten rasterbasierten Daten, abgeleiteten Daten und digitaler Einbettung.
VRVis ist Gründungsmitglied von Austrian BioImaging/CMI. Dies ist ein professionelles Konsortium aus verschiedenen österreichischen Forschungseinrichtungen und die offizielle Euro-BioImaging Initiative Österreichs.
Im Projekt "Mars-DL" wird erforscht, wie ein Deep Learning-System durch Objekt- und Mustererkennung die Arbeit von Planetenforscherinnen und -forschern unterstützen kann. VRVis hat für dieses Projekt die Funktionalität von PRo3D erweitert, um Shatter Cone-Trainingsbilder automatisch zu rendern.
Visual Computing für die Medizin: Bildverarbeitungslösungen für neue Anwendungen in der Radiologie.
Um die Qualitätskontrolle und Qualitätssicherung von Glasartikeln zu automatisieren, entwickeln wir in diesem Projekt neue Methoden aus dem Bereich der visuellen Analytik und des maschinellen Lernens.
Die langfristige Vision dieses angewandten Forschungsprojekts ist die Nutzung der verfügbaren Datenressourcen zur Verbesserung der bildbasierten Diagnostik auf der Grundlage komplexer Daten in der täglichen klinischen Routine.
Visual Computing-Techniken zur automatisierten Erkennung von Osteoporose und Osteoarthritis.